e
q
u
e
s
t
a
d
e
m
o < back
Sub-setting
Sub-setting DEFINITION
Sub-setting is a method of selecting a predefined data sub-set necessary for testing some particular development iteration of the code at specified environment. The sub-setting is usually performed before anonymization activity happens or in conjunction with the anonymization. Two ways to sub-set** are:
1. create a database schema and populate it with partial data set;
2. load a complete production data set and reduce it based on the requirements and referential constraints.
DEVELOPMENT LIFECYCLE
Let's consider the data origination and movement in the development lifecycle.
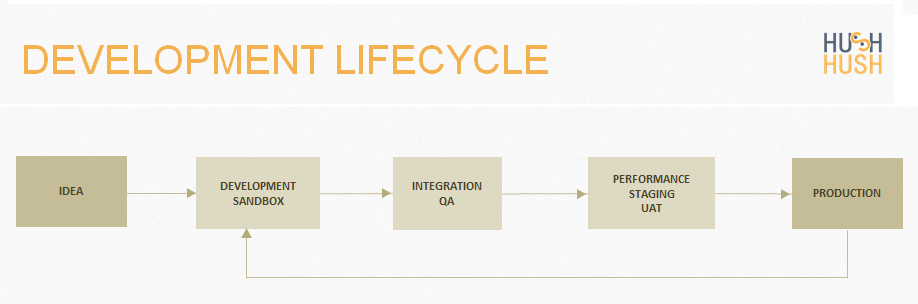
DEVELOPMENT ENVIRONMENT
developing from scratch
Any development starts with the idea, which translates into code, and this code is tested with some data. Test use cases define which data to use and create. At this stage, it is important to find data sources, and the random data masking components that contain data sets are provide easy means to create data. Such are Address, First and Last Names, Social Security Number, Credit Card, etc., as well is the 'regular expression' component. For an example of creating a set of random credit card numbers, use this video:
Developers could create the rest of the random sets in similar fashion.
The amount of data necessary to do tests in that stage of the development is usually the bare minimum, and is used mainly for functional requirements. Of course, non-functional requirements are taken into account in the architecture, but the time to test them is usually on a bigger and more system-like environment than the developer's sandbox.
This development stage is used to create the first iteration(s) of code, before exiting into the production environments.
developing within mature application
Often times, especially in the big organizations, development uses data of existing big systems. Either one needs to develop a new system or a set of new features for existing system, developers would define data necessary for testing as "all the existing master data plus some transactional". They would need existing schema and a way to populate both master and transactional data sets. The easiest way is to move such data from existing production systems, master data repositories, etc. If master data repositories do not exist or are not managed centralized, the way developers would do it often times looks the following:
SELECT * FROM
(SELECT ROW_NUMBER()
OVER (ORDER BY Country) AS [CountryId],
[Country],[CountryCode]
FROM (SELECT DISTINCT COUNTRY,[CountryCode] FROM [dbo].[Sales]) as Country) AS Countries
resulting in a sample data set, such as
CountryId Country CountryCode
1 Canada CAN
2 Mexico MEX
3 United States USA
However, in denormalized databases or staging databases, country and its code are often part of the transactional entities. In these cases, transactional data selection is based on the use case requirements:
SELECT [Address1], [Address2], [City], [StateProvince], [Country], [ZipCode]
FROM [dbo].[Sales]
WHERE [Distribution Code] in ('CAN', 'USA', 'MEX')
resulting in
Address1 Address2 City StateProvince Country ZipCode
1123 Amazing Street #12 Los Angeles CA United States 90001
5438 Cognitive Ave. #99 Toronto ON Canada H0H 0H0
462 San Felipe Blvd. #5 Mexicali BN Mexico 50-57
In the above example, sub-setting is logical and is based on use case for specific sales in specific distribution area.
Sometimes, specific logic is not important but number of records is and then percentage or specific number of records define the set:
SELECT TOP 4 [Address1], [Address2], [City], [StateProvince], [Country], [ZipCode]
FROM dbo.Sales
resulting in
1123 Amazing Street #12 Los Angeles CA United States 90001
1123 Amazing Street #34 Los Angeles CA United States 90001
5438 Cognitive Ave. #99 Toronto ON Canada H0H 0H0
462 San Felipe Blvd. #5 Mexicali BN Mexico 50-57
TEST ENVIRONMENTS
When an iteration of code development is complete, often times the developers push the code to the continuous integration environment
and/or to the testers who do testing manually or in automated mode/ In such environments, the amount of test cases increases Testers use these environments to test new features in more detail, to test code regression, and to test certain non-functional requirements such as ease of product use, security, reliability, etc.
Continuous integration environments are used in the teams utilizing best engineering practices based on a method first mentioned by Grady Booch and later adopted by extreme programming agile community. QA or testing environments are either used in manual mode or in automated mode and require significantly more data. The purpose of testing/QA environments is to cover majority of the use cases , new and those already in production that might be affected by the changed functionality. In ideal situation, the complete data set would be needed, yet, moving a complete data set affects the deadlines. Thus, the compromise, in this stage, is to use the records count that goes not in numbers but in different gradations of bytes: MB,GB,TB. Often times, testers would need to move a percentage of the entire data set. The rationale under such sub-setting is a supposition that all main test cases would be covered within certain percent of the data set. On top of that selection, one could add just those test cases that need to be covered specifically. If using a query to sub-set, here is an example of retrieving a percentage of records from the sales table:
SELECT TOP(30) PERCENT [SalesRep], [YearSummary], [Address1], [Address2], [City], [StateProvince], [Country], [ZipCode]
FROM [dbo].[Sales]
ORDER BY [Country] DESC
PERFORMANCE TESTING, LOAD TESTING, USER ACCEPTANCE TESTING, AND STAGING ENVIRONMENTS
Let's introduce some definitions to understand the difference in the nuances of different testing.
Performance Testing Environment contains a data set that allows to establish benchmarks on system performance metrics, usually those accepted in the industry. It is not used to find functional gaps and bugs.
Load Testing Environment is used to test systems under predefined load patterns. The goals are to find defects in application related to buffer overflow, memory leaks, mismanagement of memory. Another goal is to understand upper limits of load under which the application is still be able to manage its functionality.
In heavy transactional applications, metrics for benchmarking and load include CPU loads, network loads, Disk I/O and memory utilization.
Staging Environment purpose is to stage specific scenario applied to the database / code base as it is currently in production - be it a deployment or a user acceptance.
User Acceptance Testing Environment (or UAT) , as the name implies, allows users test the new version of the application from their perspective, as if they were using the code and data already deployed.
All of the above environments usually require a complete data set.