e
q
u
e
s
t
a
d
e
m
o < back
Data Masking Components: Address
{TOC}
" Address "
API Reference, CLR Reference (links)
Usage Instructions
Purpose
The purpose of the component is to randomly mask an element of address that includes street number. Often times referred as Address 1, this element usually consists of a street number, street direction, name, and suffix/abbreviation. An example would be 123 North Cherry Lane Street.
Algorithm
Description
 Address component takes street address in one of the characters data types both ASCII and unicode (char, nchar, varchar, nvarchar, text, ntext) as an input and produces a street address in the same format as an output in the form of Street Number_Street Name_Street Predicate. The output of the address component is random. It does not guarantee uniqueness of the addresses that are produced although it produces more than a million combinations in creating addresses so that statistical variation of results is high.
Address component takes street address in one of the characters data types both ASCII and unicode (char, nchar, varchar, nvarchar, text, ntext) as an input and produces a street address in the same format as an output in the form of Street Number_Street Name_Street Predicate. The output of the address component is random. It does not guarantee uniqueness of the addresses that are produced although it produces more than a million combinations in creating addresses so that statistical variation of results is high.
|
API Reference, CLR Reference (links)
Usage Instructions
| 1. Configure a source that contains the column with the element of address. A source could be connected to any database, including but not limited to SQL Server , Oracle, Sybase, mySQL, as well as a file. |
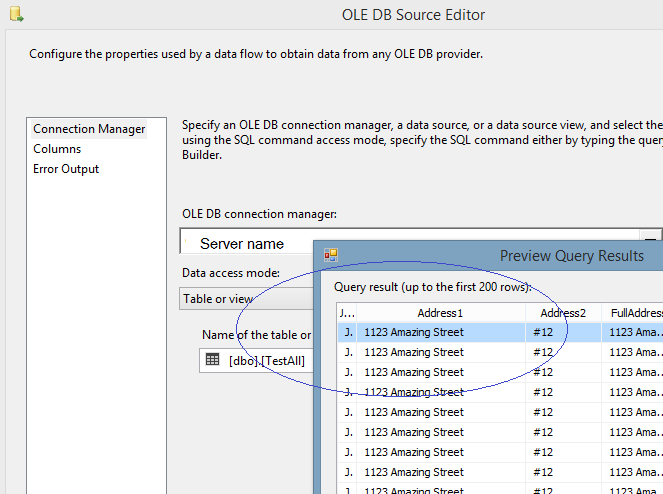
|
| 2. Drag and Drop "Masking Address" data masking component, connect the source and the "Masking Address" data masking component with the data flow path: |
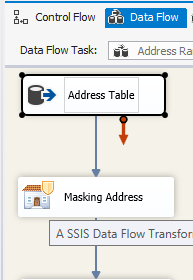
|
| 3. Now, the data flow path (the blue arrow) passes proper meta-data and data to the "Masking Address" data masking component. If you click on the data flow path, you will see: |
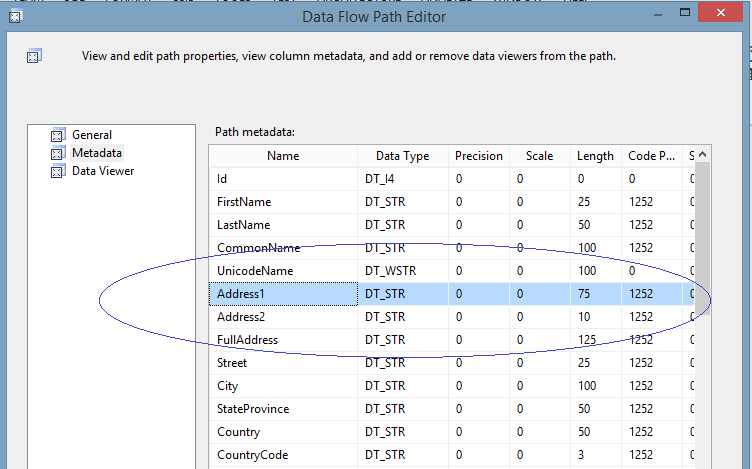
|
| 4. Now that the metadata for the "Masking Address" data masking component exists, and values are passed into it, please open the component editor: |
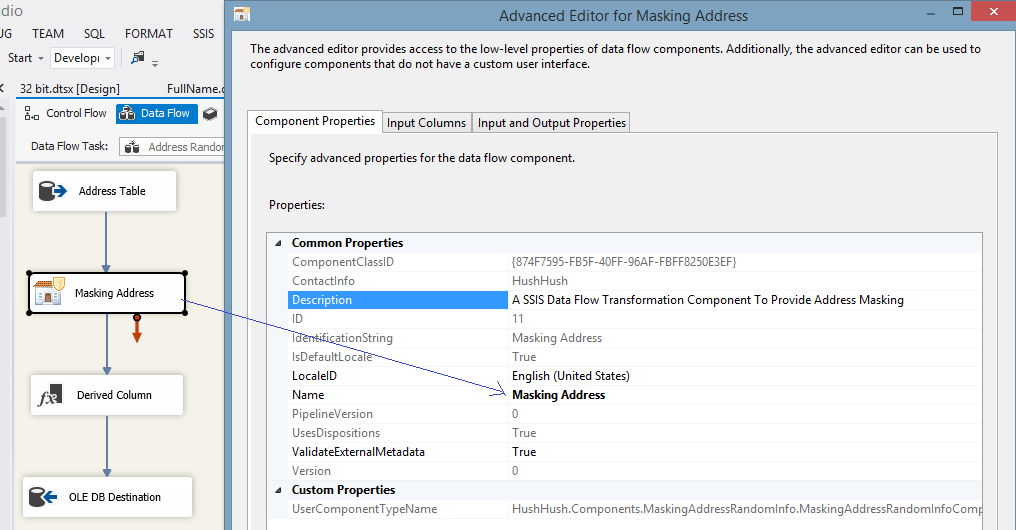
|
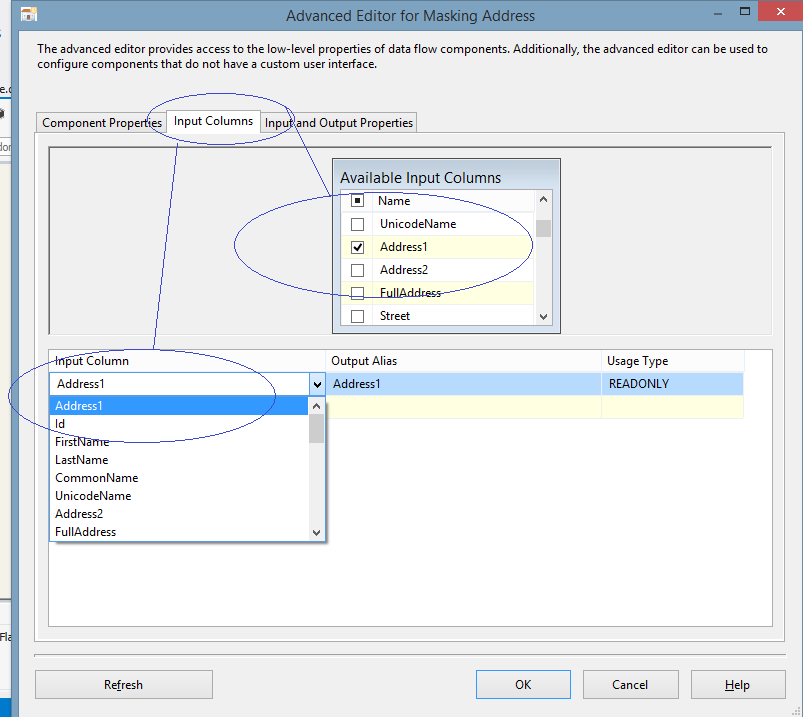
| 5. In the second tab of the component editor, "Input Columns", there are available input columns. Please choose only the columns that you will be masking with the random address substitution algorithm. You could either check-mark it or choose from the drop-down of the available columns: |
|
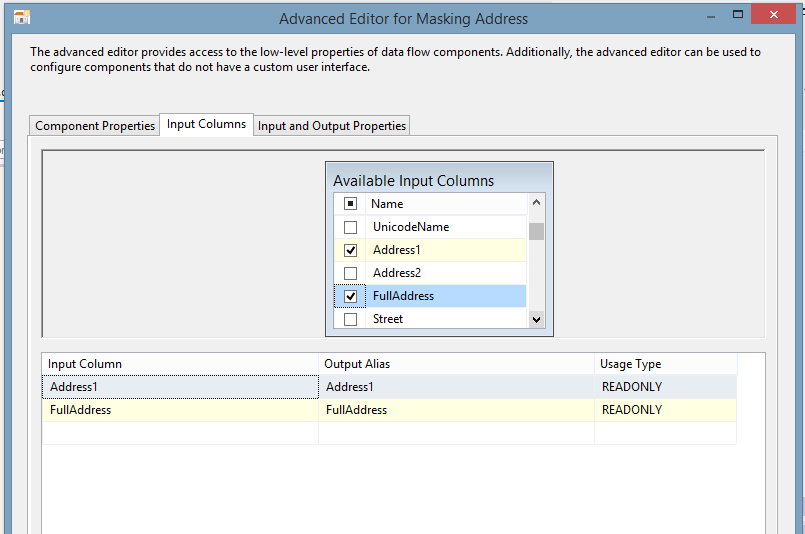
| 6. Please, notice that you can mask at the same time two or more columns with the same algorithm: |
|
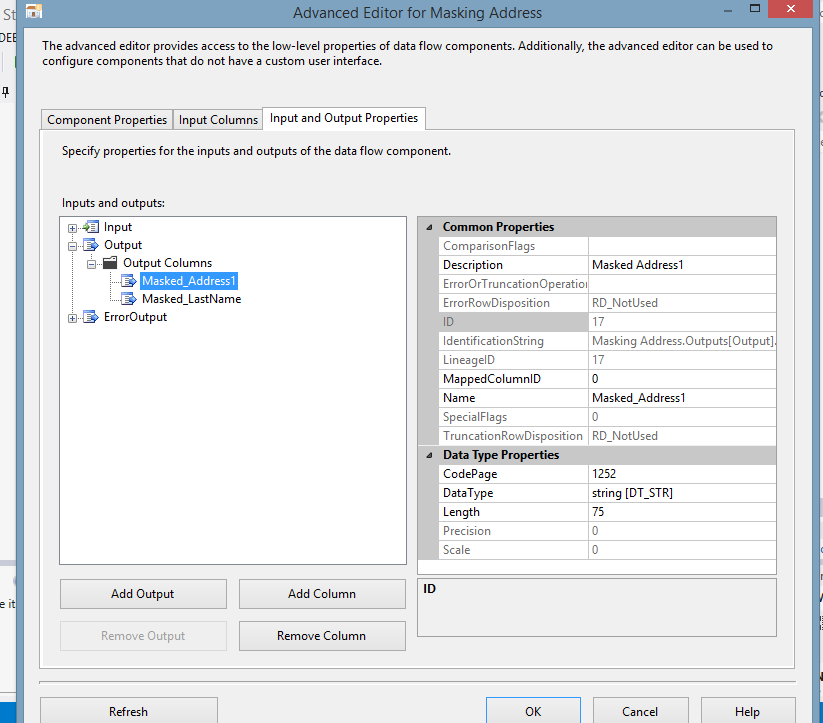
| 7. Choosing the column(s) will create a new column(s) with the prefix “Masked_field”. This is the column that will hold an obfuscated value(s) of the same data type, code page and length: |
|
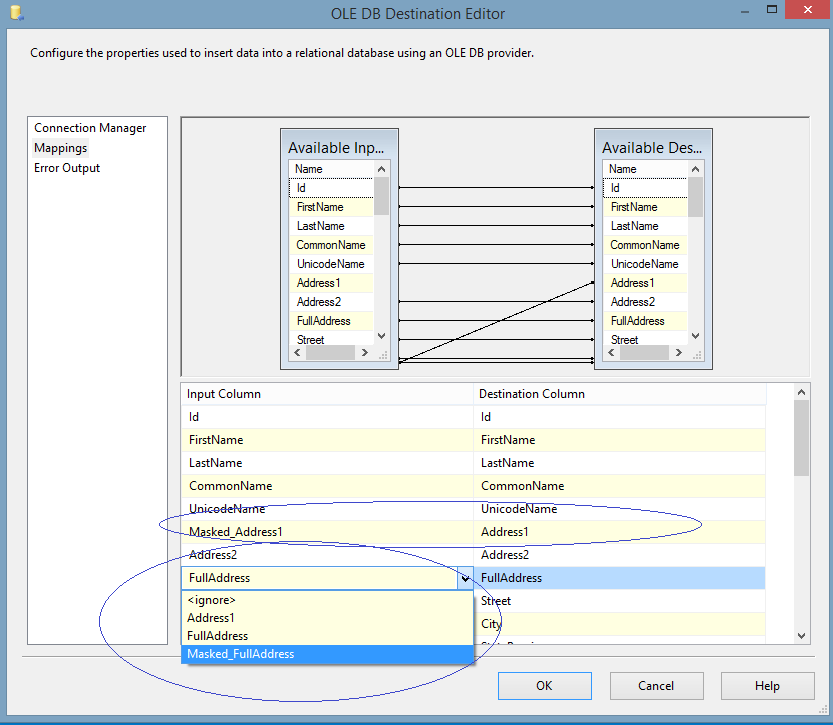
| 8. Create a connection manager for the destination and configure destination component. Read the example instructions on how to configure different SSIS connection managers and destination components here. In the connection manager, in the tab “Mappings”, specify that you want newly created "Masked_field" to be a field replacing the original value. For that, just click on the available input columns, choose the masked value, and map to the “Available Destination Columns” |
|
| 9. Now, all the configurations are complete for the valid values. You can run the package with the Address Data Masking component, and see the results of data masking: |
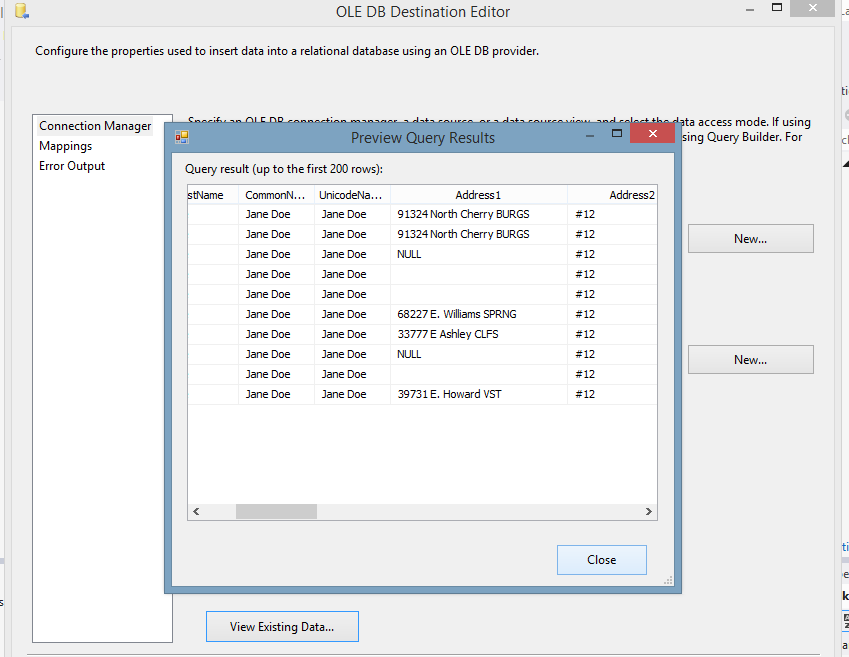
|
Error Handling
| 10. If, however, there are invalid values in the package's source, one would need to configure error handling. Invalid values are those that are not conforming to the rules of the entity. To handle invalid values, each data masking component has error handling data flow ( the red arrow). One needs to create an error destination connection and connect the red arrow with this destination. As the connection is made, one needs to configure the state of failure: “Fail”,”Ignore” or “Redirect”. |
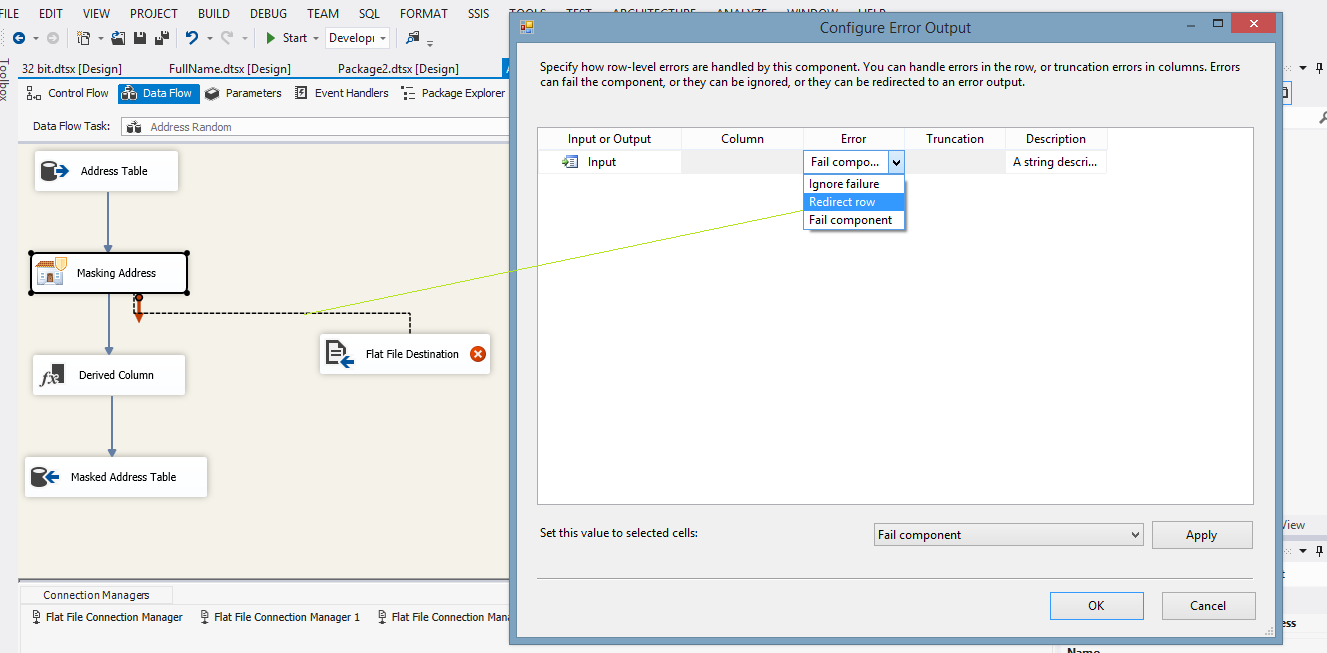
|
| 11. It is recommended that one re-directs the output into the error destination, so that later one be able to analyze and process data for quality purposes. |
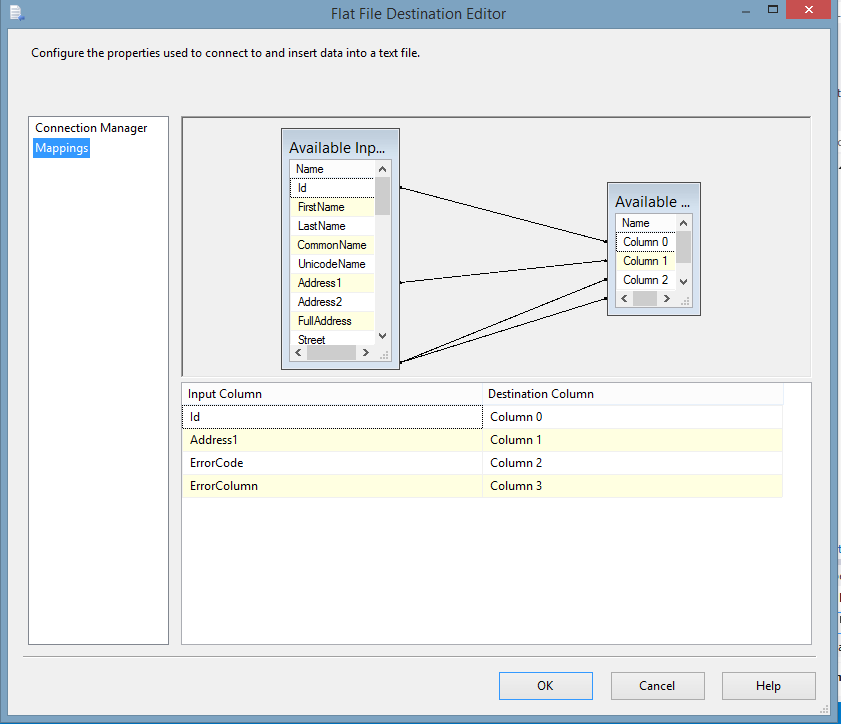
|
| 11.The data that did not confirm to the components' rules can be fixed in production and/or processed with the Generic Alpha Numeric component. | |