




The Source of Confusion
So, Ok, you have heard about data masking, de-identifying, anonymizing, scrubbing, and tokenization, and... now you are confused. You are not quite certain how to distinguish between them all. Everybody in the industry takes a different position on whether they are the same concept, indeed.
The first stop for finding the definitions is international standards. The standards provide commonly accepted definitions and requirements among the practitioners around the world. Yet, in case of the data de-identification or data masking, there is no mentioning of the term in existing ISOs. The term that ISOs mention (or in particular the ISO/TS 25237) is Pseudonymization ( ISO/TS 25237: Health informatics – Pseudonymization, First edition, 2008-12-01 (Informatique de santé — Pseudonymisation))
Another place for definitions would be compliance bodies' documents - and we have some help here from HHS with their guidance on "Safe Harbor" and 18 elements of data masking.
If the definitions are not clear enough, there is plenty of information on the internet and some books, with the one of the most popular by Khaled el Emam and Luk Arbuckle "Anonymizing Health Data".
Sometimes these internet sources and the books add to the confusion. For example, they would mention that data masking is done on the elements that are not later used in analytics, and as examples will introduce social securities and names as subjects for data masking versus de-identification. Such claim may confuse a lot of people as indeed social security of one person may be a subject to analytical reports on their many health ailments by health insurance companies, which also use data de-identification techniques as per both HIPAA and GLBA - and such attributes as dates of births may be omitted in the report on water quality and its consumers per geographic region. Last names may make more sense in such reports, as they might indicate some ancestral vertical and correlation. Thus, whether to base de-identifying versus masking definition on such preposition would not be quite accurate.
Some of the sources consider the functional definition in distinguishing data masking and de-identification. In particular, some practitioners distinguish between simply replacing the values without analysis and making the whole analysis of the attributes and complete model, in other words, creating a privacy risk model first and figuring out how to change the data, second. This distinction indeed calls for the philosophical discussion about indirect identifiers and statistical probabilities in correlations. The good point here would be WHO will be doing the analysis of risks and whether i)t can be automated and to which degree.
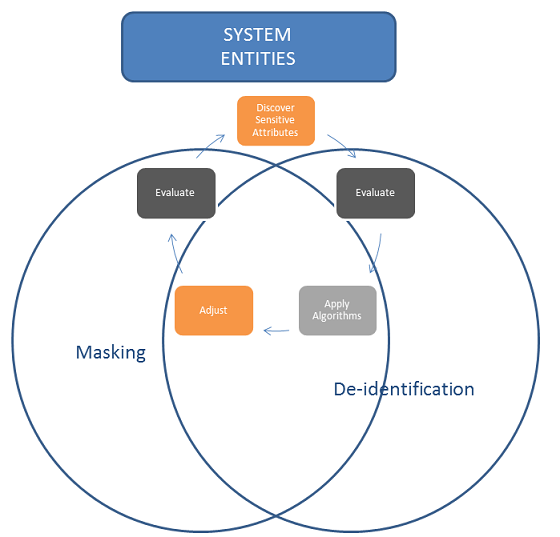
However, majority of these definitions distinctions are mainly used for the marketing purpose. Data masking and de-identifying could be used interchangeably, what's important is to understand the problem's essence and methods of resolving it.
Again, the Eighteen Pillars of HIPAA
HIPAA's guidelines on identifying necessary elements for data masking/de-identification in Safe Harbor are mainly based on the research done by Latanya's Sweeny and her at- the -time calculations on the probability of re-identification. She is basing the research on the most common, available to the general public banks of statistical data. These banks ( zip code population statistics, public records of birth, housing sales data) are easily available to the general public and as such make data numbers significantly less secure. There is also census data that has become less available in the recent years - due to the debate of privacy versus public knowledge leaning toward privacy. The availability of such data makes the data with statistical distributions significantly easier to de-identify. Thus, securing this data properly allows for "Safe Harbor" - the protection against the most common threat. In order to properly secure such data, it is recommended to use the substitution algorithms that preserve referential integrity, at the same time disturbing statistical distribution.
The Real Challenges of Sensitive Data Domain
Further research delves into less popular data statistics and presents the public with the rather philosophical question of the overall knowledge distribution and aggregation. In their paper on l-diversity, besides the homogeneity attack principle, the most interesting aspect that authors point out is the "Background Knowledge Attack" (Machanavajjhala, Kifer, Gehrke, and Venkitasubramaniam (2007)). It relates to the knowledge that the person looking at sensitive data may have of the statistics of specific attributes.
The authors mention an interesting fact as an example, "that knowing that heart attacks occur at a reduced rate in Japanese patients could be used to narrow the range of values for a sensitive attribute of a patient's disease." ( Wikipedia) This fact is indeed interesting as very small percentage of the population will know about such correlations: unless widely popularized by such media outlets as popular movies, books, articles in the major consumer publications, or popular games, one would hardly know such facts unless doing a focussed research in the medical papers. The medical practitioners themselves might not be aware of such facts, yet the probability of re-identification exists. It is hard to find out how well-disseminated the knowledge is among general public. However, as in general research widens in the sphere of genetic engineering, the practitioner would make a safe assumption to mask with this or that technique attributes related to the genetic research such as ethnicity, familial associations, genetic markers, etc.